
در حالی که مدل های رگرسیون خطی ابزار پیش فرض مورد استفاده بسیاری از تحلیلگران منابع انسانی بوده اند، اما همیشه بهترین راه برای ثبت الگوها در داده های منابع انسانی شما نیستند. همه پدیده های منابع انسانی را نمی توان با ترسیم خطوط مستقیم توصیف کرد. در اینجا، رویکردهای مدلسازی الگوریتمی انعطافپذیرتر مانند درختهای تصمیمگیری میتوانند افزودهای ارزشمند به جعبه ابزار تحلیلگر منابع انسانی باشند.
بیایید نحوه استفاده از درخت تصمیم در تجزیه و تحلیل منابع انسانی را با جزئیات بررسی کنیم.
مطالب
درخت تصمیم چیست؟
زمان استفاده از درخت تصمیم در تجزیه و تحلیل منابع انسانی
اصطلاحات
از مثال مورد استفاده کنید
ساخت درخت تصمیم
درخت تصمیم چیست؟
درخت تصمیم یک الگوریتم یادگیری ماشینی نظارت شده است که یک مدل ناپارامتریک تولید می کند. قسمت نظارت شده به این معنی است که درخت تصمیم در شرایطی ساخته می شود که مقادیر هر دو متغیر مستقل و وابسته مشخص باشد. بخش ناپارامتریک نشان می دهد که مدل درخت تصمیم هیچ فرضی در مورد توزیع داده های اساسی ندارد.
بنابراین درختان تصمیم گیری بسیار انعطاف پذیر هستند. آنها حتی می توانند خارج از جعبه برای اهداف طبقه بندی (به عنوان مثال، نتایج طبقه بندی) و رگرسیون (یعنی نتایج عددی) استفاده شوند.
دو توسعه دهنده پیشرو برای توسعه الگوریتم درخت تصمیم معتبر هستند: جان راس کوینلان و لئو بریمن.
در حدود سال 1984، کوینلان الگوریتم درخت تصمیم خود را Iterative Dichotomiser 3 یا به طور خلاصه ID3 نامید و بعداً انواع C4.5 و C5.0 تجاری را توسعه داد. بریمن و همکارانش در برکلی الگوریتم درخت تصمیم خود را به سادگی درختهای طبقهبندی و رگرسیون – یا به اختصار CART – نامگذاری کردند و پیادهسازی آنها بیشتر در عمل مورد استفاده قرار میگیرد.
در این مقاله، ما از پیاده سازی Breiman’s CART در زبان برنامه نویسی آماری R استفاده می کنیم.
اگر میخواهید مهارتهای R خود را برای تجزیه و تحلیل منابع انسانی تقویت کنید، برنامه گواهی تحلیل افراد ما مکانی عالی برای شروع است.
زمان استفاده از درخت تصمیم در تجزیه و تحلیل منابع انسانی
درختهای تصمیم یک افزونه عالی برای جعبه ابزار تجزیه و تحلیل منابع انسانی شما هستند. آنها به راحتی اثرات غیر خطی پیچیده را در داده های منابع انسانی شما پیدا کرده و از آنها استفاده می کنند و تقریباً بدون دخالت تحلیلگر این کار را انجام می دهند.
درختان تصمیم به ویژه در شرایط خاص ارزشمند هستند:
- زمانی که داده های بسیار بعدی دارید (یعنی متغیرهای زیادی) و مطمئن نیستید که کدام یک پتانسیل پیش بینی دارند. در اینجا چند نمونه وجود دارد:
- شما ویژگی های جو تیم (فشار کاری، سبک رهبری، بازخورد، استقلال، و غیره) را بررسی کرده اید و در مورد همبستگی های جابجایی بالای کارکنان کنجکاو هستید.
- اطلاعات زیادی در مورد سابقه شغلی کارکنان دارید و در مورد همبستگی های پیشرفت شغلی (ترفیع) کنجکاو هستید.
- شما اطلاعات دقیقی در مورد تجربه کاری کارکنان خود دارید (مثلاً داده های متنی از رزومه) و کنجکاو هستید که چه چیزی با تصمیمات استخدام مرتبط است.
- زمانی که متغیر وابسته شما به طور معمول توزیع نمی شود (به عنوان مثال، داده های کج مانند حقوق و میزان غیبت)
- یا زمانی که انتظار اثرات غیر خطی را دارید، مانند چند جمله ای های مرتبه بالاتر یا شاید تعاملات و اثرات تعدیل کننده بین متغیرها، به عنوان مثال:
- شما ویژگیهای جو تیمی (فشار کاری، سبک رهبری، بازخورد، استقلال و غیره) را بررسی کردهاید و به موقعیتها/ترکیبیهایی که در آن جابجایی بالای کارمندان را تجربه میکنید علاقهمند هستید.
- اطلاعات زیادی در مورد سابقه شغلی کارمندان دارید و به موقعیتها/ترکیبیهایی که بیشترین پیشرفتهای شغلی (ترفیعات) در آنها رخ میدهد علاقهمند هستید.
- شما اطلاعات دقیقی در مورد تجربه کاری کارمندان دارید (مثلاً داده های متنی از رزومه ها) و کنجکاو هستید که کدام مجموعه از تجربیات ممکن است استخدام های موفق را پیش بینی کند.
- انتظار دارید که بین دوره تصدی و عملکرد فروش رابطه وجود داشته باشد اما خطی نباشد. شما انتظار عملکرد پایین در شروع، عملکرد بالا در طول سال های 2 تا 5 و سپس کاهش آهسته را دارید.
اصطلاحات
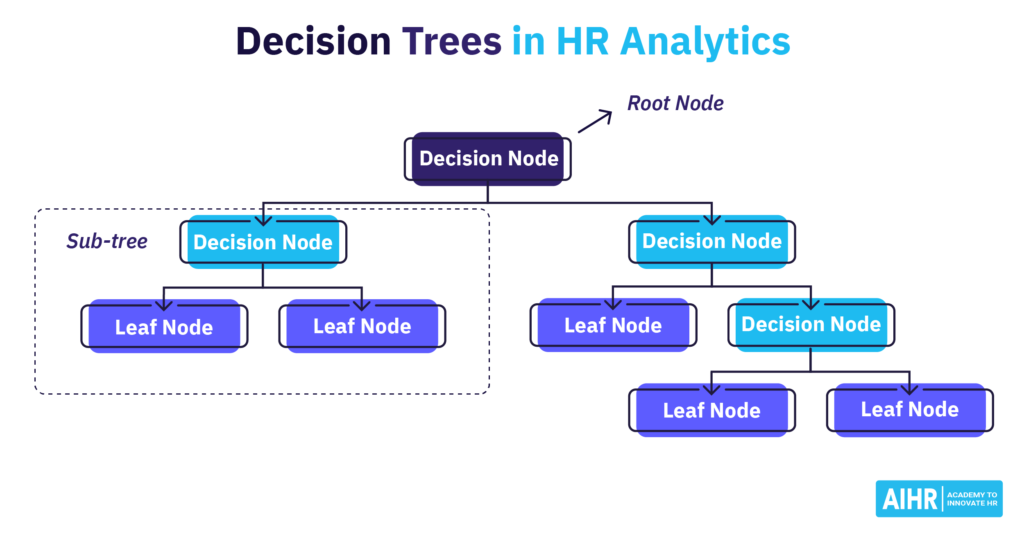
ایده اصلی پشت الگوریتم درخت تصمیم، نمایش داده ها به عنوان مجموعه ای از قوانین تصمیم گیری است که ساختاری درخت مانند را تشکیل می دهند.
شکل 1 زیر یک درخت تصمیم را نشان می دهد و شما باید آن را از بالا به پایین بخوانید. شما از بالا با یک گره ریشه شروع می کنید. هر گره بعدی در درخت یا یک گره تصمیم است – که در آن داده ها بر اساس شرایطی به زیر مجموعه ها تقسیم می شوند – یا یک گره برگ – که در آن یک زیر مجموعه داده ساکن است که بیشتر تقسیم نمی شود.
هر گره تصمیم گیری یک آزمون مشروط را تشکیل می دهد که منجر به یک قانون تصمیم گیری دودویی (بله/خیر) می شود، مانند «آیا این کارمند مدیر است؟»، «آیا این کارمند پتانسیل بالایی دارد؟»، یا «آیا این تیم بیش از شش کارمند دارد. ؟».
درخت به دست آمده شبیه یک نمودار جریان است. در اینجا، هر گره یک تست شرطی برای یک متغیر مستقل ( که ویژگی نیز نامیده می شود) را نشان می دهد. هر شاخه نتیجه آزمایش را نشان می دهد و هر گره برگ زیرمجموعه ای از داده های HR را نشان می دهد که در آن مدل مقداری میانگین یا احتمال را تخمین می زند. متغیرها و مقادیر برش بر اساس ارزش افزوده آنها برای پیشبینی/طبقهبندی متغیر وابسته (که هدف نیز نامیده میشود) انتخاب میشوند.

از مثال موردی استفاده کنید
بیایید ببینیم این درختان تصمیم چگونه کار می کنند.
در عمل، احتمالاً از درخت های تصمیم در مجموعه داده های بزرگ استفاده خواهید کرد. این هم از نظر تعداد کارکنان شامل و هم از نظر تعداد متغیرهای مدل شده است. با این حال، یک مثال کوچک به توضیح عملکرد درونی آن کمک می کند.
ما از مجموعه داده HR نشان داده شده در جدول 1 استفاده می کنیم. این مجموعه شامل اطلاعات معمولی است که در سیستم اطلاعات منابع انسانی خود پیدا می کنید و 18 کارمند را شامل می شود.
داده های ما شامل سه متغیر مستقل است: نوع شغل ، ارزیابی احتمالی ، و چند سال از آخرین ترفیع کارمند می گذرد.
هدف ما پیشبینی گردش مالی متغیر وابسته است که نشان میدهد آیا یک کارمند سازمان را ترک کرده است یا خیر. این یک مشکل طبقه بندی را نشان می دهد، زیرا ما می خواهیم پیش بینی کنیم که آیا کارکنان باید با توجه به گردش مالی خود به عنوان “بله” یا “خیر” طبقه بندی شوند.
جدول 1: نمونه مجموعه داده با اطلاعات کارکنان گرفته شده از HRIS معمولی
| نام کارمند | نوع شغل | بالقوه | سالها از ارتقاء | گردش مالی |
| آلفرد | مدیر | بالا | 6 | خیر |
| بوجین | مشارکت کننده فردی | کم | 6 | خیر |
| کوری | مشارکت کننده فردی | متوسط | 3 | خیر |
| دنیس | مشارکت کننده فردی | بالا | 10 | بله |
| اورهارد | مشارکت کننده فردی | کم | 2 | خیر |
| فینی | مشارکت کننده فردی | متوسط | 10 | خیر |
| جورج | مشارکت کننده فردی | متوسط | 6 | خیر |
| هرمان | مشارکت کننده فردی | بالا | 1 | خیر |
| یوجا | مشارکت کننده فردی | کم | 7 | خیر |
| جک | مدیر | متوسط | 8 | خیر |
| کنستانتین | مدیر | کم | 0 | خیر |
| لوئیس | مشارکت کننده فردی | متوسط | 4 | خیر |
| ماکسیم | مشارکت کننده فردی | متوسط | 1 | خیر |
| نبوسو | مشارکت کننده فردی | بالا | 0 | خیر |
| اولاو | مشارکت کننده فردی | بالا | 5 | بله |
| Pjotr | مدیر | متوسط | 1 | خیر |
| کویرین | مشارکت کننده فردی | بالا | 7 | بله |
| رودریگا | مشارکت کننده فردی | بالا | 6 | بله |
هدف اصلی درخت تصمیم این است که این کارمندان را به زیرگروه هایی تقسیم کند که «خالص ترین» جداسازی طبقات را داشته باشند. این بدان معناست که گرههای برگ آن باید در درجه اول شامل کارمندانی باشد که همگی «بله» دارند، یا همه «نه» در گردش متغیر هدف دارند.
ساخت درخت تصمیم
فرآیند درخت سازی با مجموعه داده کامل 18 کارمند در گره ریشه درخت ما شروع می شود. در اینجا هنوز هیچ انشعابی در نظر گرفته نشده است. بنابراین، این گره اکنون شامل 100٪ از مجموعه داده است. کارکنان این گره دارای مقدار متوسط 0.22 بر روی متغیر هدف هستند یا به عبارت دیگر، 22٪ دارای ارزش گردش مالی “بله” هستند و شرکت را ترک کرده اند. این بدان معناست که اکثر این گره ریشه متعلق به کلاس غیر گردش مالی (“No”) است، بنابراین این مقداری است که درخت تصمیم ما برای همه کارکنان در این گره پیش بینی می کند.

الگوریتم درخت تصمیم اکنون باید قاعده تصمیم گیری را پیدا کند که این دو کلاس را به بهترین شکل از هم جدا می کند. از این رو، تقسیم این کارمندان به زیرگروه ها به هر طریق ممکن تکرار می شود. تمام مقادیر قطع ممکن برای هر یک از سه متغیر مستقل در مجموعه داده ما بررسی و ارزیابی میشوند.
با شروع با متغیر Job type ، الگوریتم با دو مقدار منحصر به فرد روبرو می شود – Manager و Individual Contributor . این دو روش یکسان برای تقسیم داده ها ارائه می دهد، که همه مدیران را از غیرمدیران یا همه مشارکت کنندگان فردی را از مشارکت کنندگان غیر فردی جدا می کند.
برای متغیر پتانسیل ، سه تقسیم ممکن است، کارمندان با پتانسیل کم، متوسط یا زیاد را از همکارانشان جدا می کند.
برای متغیرهای عددی، درخت تصمیم ابتدا مجموعه ای از مقادیر منحصر به فرد را استخراج می کند. سپس، میانگین را برای هر جفت دو مقدار بعدی محاسبه می کند. این مقادیر میانگین بهعنوان برشآف استفاده میشوند، جایی که درخت تصمیم کارمندانی را که امتیاز کمتری دارند از افرادی که امتیاز بالاتر از برش دارند، جدا میکند. بنابراین، برای متغیر Years since Promotion ، درخت تصمیم در مجموع هفت تقسیم را برای مقادیر برش 2، 5، 7 و 9 بررسی می کند.
به طور کلی، جدول 2 مجموع 9 روش را برای تقسیم مجموعه داده HR در گره ریشه نشان می دهد.
جدول 2: تمام شکاف های ممکن در گره ریشه، طبقه بندی شده بر اساس ناخالصی جینی (به زیر مراجعه کنید).
| قاعده تصمیم گیری | ناخالصی جینی |
| پتانسیل == زیاد | 0.190 |
| پتانسیل == متوسط | 0.283 |
| نوع شغل == مدیر | 0.317 |
| نوع شغل == مشارکت کننده فردی | 0.317 |
| پتانسیل == کم | 0.317 |
| سالها از ارتقاء < 2 | 0.317 |
| سالها از ارتقاء < 7 | 0.321 |
| سالها از ارتقاء < 9 | 0.326 |
| سالها از ارتقاء < 5 | 0.331 |
الگوریتم درخت تصمیم باید کمیت کند که هر یک از این تقسیمها برای یافتن و استفاده از بهترین تقسیم چقدر خوب است. معیارهای چندگانه ای برای تعیین خوب بودن یک تقسیم باینری وجود دارد، اما رایج ترین مورد استفاده ناخالصی جینی است.
ناخالصی جینی میانگین احتمال برچسب گذاری اشتباه یک مشاهده را هنگام استفاده از یک برچسب تصادفی که از مجموعه برچسب های فعلی گرفته شده است، اندازه گیری می کند. ممکن است پیچیده به نظر برسد اما در واقع کاملاً شهودی کار می کند.
وقتی همه برچسبهای ترسیم شده بهطور تصادفی درست باشند، ناخالصی جینی 0 است. این حداقل مقدار جینی ممکن است، و فقط در گرههای خالص رخ میدهد – مانند زیر گروهی از کارمندان که همگی در گردش مالی «بله» میگیرند. در این گرههای خالص، هر برچسبی که بهطور تصادفی از چنین زیرگروهی همگن کشیده میشود، صحیح است.
در زیرگروه هایی که تعداد کارکنان متعلق به کلاس گردش مالی «بله» به تعداد کارکنان «نه» وجود دارد، ناخالصی جینی 0.5 دریافت خواهید کرد. در اینجا، تنها نیمی از برچسبهایی که بهطور تصادفی کشیده شدهاند، درست هستند. در مجموع، ناخالصی جینی کم، زیرگروهی همگن تر را منعکس می کند، که درخت تصمیم به دنبال آن است. به دنبال یافتن قوانین تصمیم گیری است که منجر به پیش بینی های دقیق می شود.
درخت بهترین شکاف را با استفاده از قانون تصمیم گیری که منجر به کمترین ناخالصی جینی می شود، پیدا می کند. پتانسیل == تقسیم زیاد کمترین ناخالصی جینی (.190) را تولید می کند و بنابراین بهترین جداسازی موارد گردش مالی از کارکنان باقی مانده را ایجاد می کند. از این رو، این قانون تصمیم گیری در گره ریشه در شکل 3 انجام می شود، اگرچه نام آن توسط برنامه ما متفاوت است.

این دو شاخه با گره های مرتبط تولید می کند. همه کارکنان با پتانسیل کم و متوسط به گره سمت چپ اختصاص داده می شوند که 61٪ از کل مجموعه داده را نشان می دهد. هیچ یک از آنها برنگشتند، بنابراین این یک گره خالص است. این امر از جمله باعث ناخالصی جینی پایین برای این قاعده تصمیم گیری شد. از آنجایی که نسبت گردش مالی در این گره 0.00 است، درخت تصمیم “نه” را برای همه مشاهدات پیش بینی می کند.
گره سمت راست اکنون شامل همه کارکنان با پتانسیل بالا است. این نشان دهنده 39٪ از مجموعه داده است. نسبت گردش مالی در اینجا 0.57 یا 57٪ است و بنابراین درخت تصمیم گیری گردش مالی این گروه را “بله” پیش بینی می کند.
درخت تصمیم به عنوان یک گره خالص، دیگر شکاف های بیشتری را برای گره سمت چپ در نظر نمی گیرد. بنابراین این گره سمت چپ را می توان یک گره برگ در نظر گرفت.
الگوریتم درخت تصمیم همان فرآیند را برای گره سمت راست تکرار می کند. ناخالصی جینی تمام تقسیمات ممکن را محاسبه می کند (جدول 3) و قاعده تصمیم گیری را انتخاب می کند که کمترین ناخالصی جینی را تولید می کند (شکل 4 را ببینید).
جدول 3: تمام تقسیمات ممکن در گره 3 – شامل همه کارکنان با پتانسیل بالا – طبقه بندی شده بر اساس ناخالصی جینی
| قاعده تصمیم گیری | ناخالصی جینی |
| سالها از ارتقاء < 2 | 0.229 |
| سالها از ارتقاء < 7 | 0.343 |
| نوع شغل == مدیر | 0.381 |
| نوع شغل == مشارکت کننده فردی | 0.381 |
| سالها از ارتقاء < 5 | 0.405 |
| سالها از ارتقاء < 9 | 0.429 |

در این مرحله، تقسیم سالهای پس از ترفیع کوچکتر از 2 بهترین، موارد گردش مالی باقیمانده را از کارمندانی که ماندهاند جدا میکند. دوباره، یک گره برگ خالص در سمت چپ ظاهر می شود (گره 4)، که شامل همه کارکنان با پتانسیل بالا است که در دو سال گذشته ارتقا یافته اند. این دو کارمند (11 درصد از نمونه) 0 درصد احتمال جابجایی را نشان می دهند.
گره 5 در سمت راست شامل همه کارکنان با پتانسیل بالا است که برای دو سال یا بیشتر منتظر ارتقاء هستند (28٪ از نمونه). آنها 80 درصد احتمال گردش مالی را نشان می دهند.
از آنجایی که گره 5 هنوز خالص نیست، ممکن است شکاف های بیشتری برای درخت تصمیم در نظر گرفته شود. فعلاً از جزئیات Gini صرفنظر می کنیم، اما شکل 5 بهترین جداسازی بعدی را بر اساس اینکه نوع شغل مدیر است نشان می دهد. اگر چنین است، آنها در سمت چپ گره 6 قرار می گیرند، که باز هم یک گره خالص با گردش 0٪ است. به طور مشابه، گره 7 در سمت راست نیز خالص است، با مشارکت کنندگان فردی که همه آنها را برگردانده اند.

درخت تصمیم ما اکنون کامل شده است و تمام گره های نهایی گره های برگ در نظر گرفته می شوند. از طریق سه قانون ساده، درخت تصمیم ما توانست تمام موارد گردش مالی را از همکاران حفظ شده آنها جدا کند. علاوه بر این، توانست دو الگوی غیرخطی جالب را به تصویر بکشد. زمان در موقعیت (یعنی سالهای پس از ارتقا) فقط برای جابجایی کارکنان با پتانسیل بالا و فقط برای مشارکتکنندگان فردی مرتبط بود، نه برای مدیران .
کلام پایانی
شما شاهد بودید که چگونه الگوریتمهای درخت تصمیم یک افزونه عالی به جعبه ابزار یک تحلیلگر منابع انسانی تشکیل میدهند. آنها امکان کشف انعطاف پذیر و آسان الگوهای پیچیده را فراهم می کنند. علاوه بر این، مدلهای خروجی برای درک و توضیح برای دیگران – حتی ذینفعان غیر فنی – بصری هستند.
در حالی که درختهای تصمیم قطعاً با محدودیتهایی همراه هستند، ما احساس میکنیم که حوزه منابع انسانی از استفاده گستردهتر از این الگوریتمهای “یادگیری ماشینی” سود زیادی دارد.